Shift-left testing approaches
In this article, we’ll quickly cover what shift-left testing is, how it helps us find problems early in the software development-cycle, and how we can apply it to our work.

Let’s take a look at the lifecycle of a new feature that has to be developed. Starting from development and unit-tests, all the way to release and beyond.
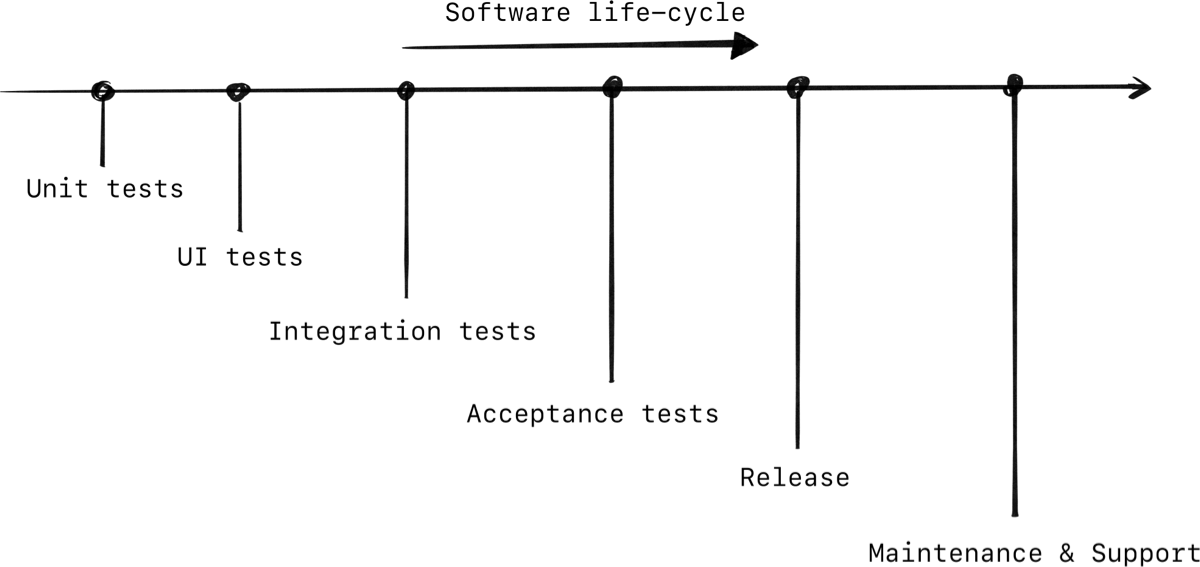
This is a generic software development lifecycle, your work will most likely have their own flavor of it.
Looking at that graph, we have a left-side and right-side. Simply put, shifting to the left means testing earlier in the software-development process. The benefits of that is that it’s quicker to find and fix issues on the left side.
Imagine a feature breaking. It’s nicer to know about this in a unit test on your local machine — left on the diagram, as opposed to a failing CI pipeline 3 hours later — a bit more to the right. Or worse, a feature breaking in production with the entire team panicking, while you’re explaining to customer service what they can share with angry customers — really far right.
Okay so that’s was an extreme example. But let’s look at more real-life scenario where we use subtle changes to move tests closer to unit-tests.
An example
Imagine we’re making a VideoUploader. This uploader has a bunch of logic. For example, it can read media from a harddisk, perform bitrate conversion, perform partial uploads and other fancy stuff related to large video files.
But most importantly, it doesn’t do everything by itself. For instance, VideoUploader uses an VideoAPI to upload things, which in turn uses a network layer underneath for the raw data calls with URLSession. It also doesn’t compress and optimize videos directly, it uses an underlying VideoCompressor for that.
Visualizing the stack we’re using, we can see specific types up top, which incorporate more generic types at the bottom.
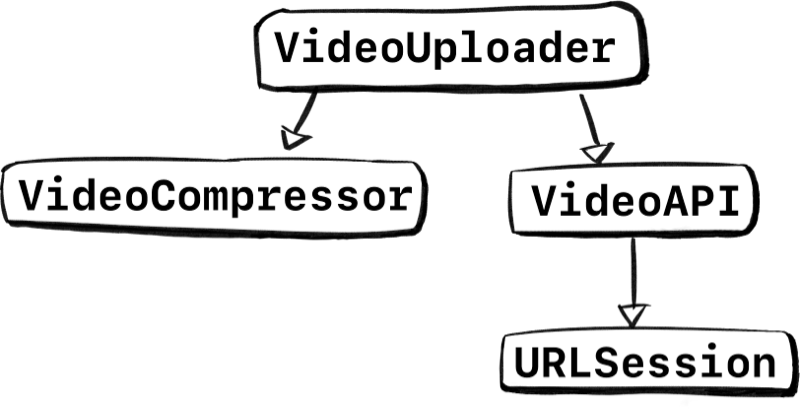
Now let’s say we want to unit-test VideoUploader. Since real network calls are something we don’t want in unit-tests, we have to mock it out.
One approach we could take is to mock VideoAPI so we can test VideoUploader.
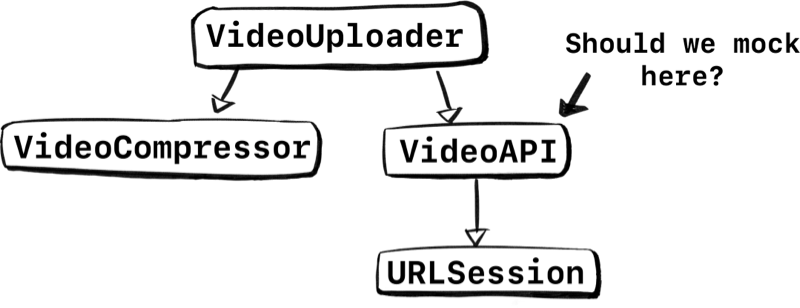
But there are two problems with this. Let’s go over them before we come up with a solution.
Problem #1: Shifting right
Let’s say we do go ahead, and we swap out VideoAPI with a VideoAPIProtocol for testing purposes. Hooray, we can now unit test VideoUploader!
But you know what this means though? The integration between VideoAPI and VideoUploader is completely gone in our tests. The VideoUploader will always have perfectly controlled networking scenarios unlike real-world scenarios.
So, the only way for us to get confidence about VideoUploader using VideoAPI is in a later stage in development. Now we have to resort to other tactics, such as additional integration tests or performing a manual test, just to make sure our VideoUploader works well with VideoAPI.
With this solution we would be shifting right, we’re making it harder and more time consuming to ensure our integration works as intended.
Problem #2: Adding holes to our types
Introducing a protocol solely for testing has a price. For example, instead of working with a VideoAPI, we decide to swap it out with a VideoAPIProtocol. Then in debug or production builds, we’ll use VideoAPI and in testing builds we’ll use a VideoAPIMock type.
However, this new protocol does nothing to help production code, it’s there to make our testing lives easier. We introduce a new protocol—thus raising complexity—and open up VideoUploader to accept custom VideoAPIProtocol implementations.
One consequence is that by looking at the codebase, you’ll see code such as let videoAPI: VideoAPIProtocol, but you can’t instantly see what this will be until runtime. For example, if you CMD+click on VideoAPIProtocol, you won’t navigate to a concrete type, you navigate to the protocol definition which can be anything at runtime, and then you have to manually search to figure out which types implement the protocol.
“But we know what’s behind the protocol. It’s VideoAPI, it’s always going to be VideoAPI in production code” some may say.
However, can you guarantee that others (and your future-self) will memorize what’s behind the protocol?
If we’re not careful, these testing protocols will slowly creep into our codebase, all across the stack. As a result we end up with an increased number of testing-holes in our codebase.
It’s not a problem if it happens here and there, and certainly not in this single use-case. But if we keep swapping types with protocols without thinking, then our codebase starts to resemble a Swiss cheese.

The point is, we can’t always avoid introducing a protocol, we have to test without network calls after all. But we want to minimize introducing protocols that make production-code more complex.
Shifting left
Let’s consider a different approach to shift our testing left and minimize the impact of testing protocols. There are at least two steps we can take:
Decomposing until we can swap out the tiniest element. So that we maximize production-code in our tests.
Trying to find a pre-existing testable component. So that we don’t needlessly introduce new testing protocols.
Let’s look at the stack again. The lowest point to test would be URLSession. Let’s try to mock in that area.
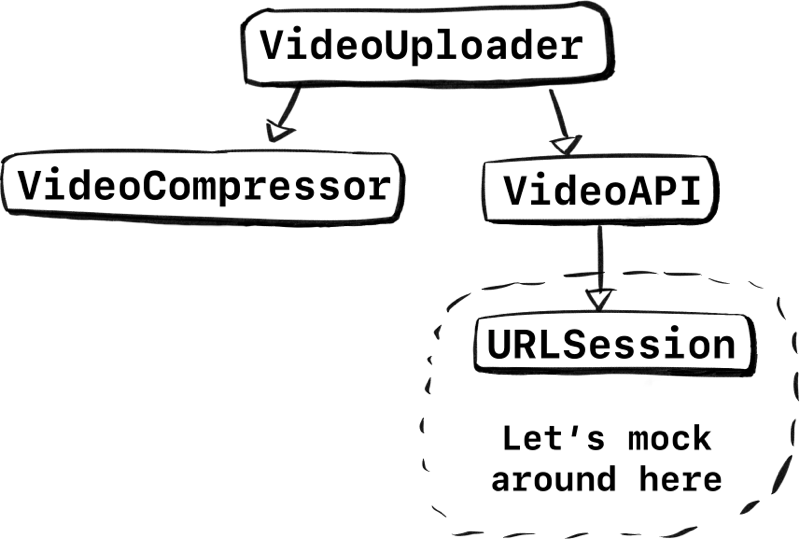
If we were to only swap out URLSession behind a protocol, we can keep most of the integration intact. Instead of swapping out VideoAPI and all the code underneath, we could only swap out URLSession at the lowest level. We keep the parsing, error handling, all that logic! That’s a lot of code we wouldn’t have tested with our earlier approach.
But, are we done? Not really. Let’s look at point two. Figure out if we can reuse something. Luckily, URLSession already has something for us, and it’s called URLProtocol.
Let’s decompose URLSession and update our graph.
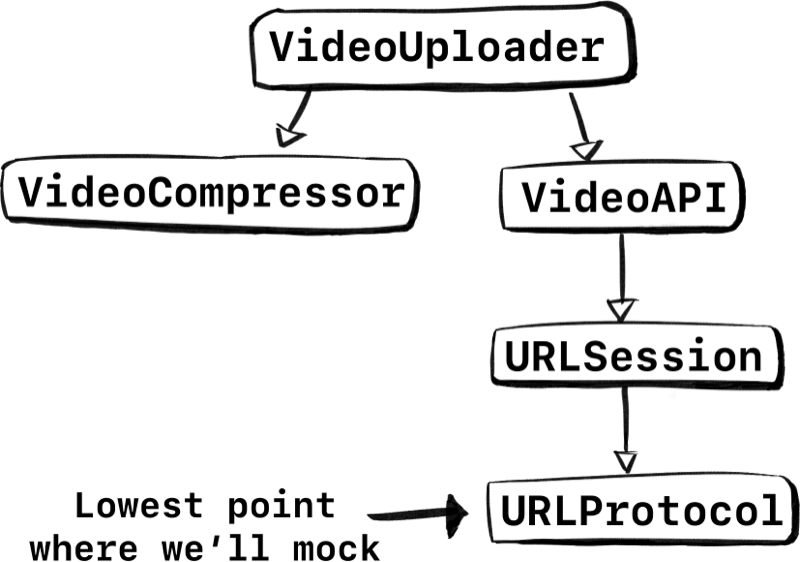
Perfect, instead of mocking URLSession, we can implement URLProtocol. Now we can fake responses ourselves. By doing so we get to keep almost the entire network stack in our unit-tests! All the way from VideoUploader down to the bits and bytes of URLSession. We keep URLSession and we don’t introduce a new protocol that our coworkers need to learn about, win-win.
![]()
Implementing URLProtocol warrants its own article. Luckily it’s quite doable. But if you don’t want to implement it yourself, then I recommend you take a look at Mocker.
Introducing a testing protocol
URLSession has a ready-made protocol for us to implement, but what if that isn’t an option?
Let’s look at another example. Compressing videos is very time-consuming. So it wouldn’t make a lot of sense to compress videos in all of our tests, maybe just one, otherwise the time to run our tests might bump from minutes to hours.
Looking at the previous example, do we swap out the entire VideoCompressor? No, we can take the same steps again. We already know there is no ready-made solution for testing. But, we can decompose. Let’s do that.
The VideoCompressor does a bunch of things. For example, it may need to use disk-caching and multithreading to handle large files. But that’s not the slowest part. The slowest part is the compression itself, the algorithm to turn bytes into a new set of bytes. Compressing the video is a matter of data in, data out.
So if we were to decompose VideoCompressor, we get the following systems:

The compression-algorithm is the part that’s slow. So that’s the tiniest component we need to swap out in our tests using a protocol.
By swapping out the algorithm we pay the price of introducing a new testing protocol. But it’s not that bad. We only swap out the tiniest part at the deepest level while we get to keep everything else. The disk-caching, multithreading and the VideoCompressor calling the algorithm is still part of our unit-tests!
Swapping out the algorithm is a much better concession than ruthlessly swapping out the VideoCompressor and realizing in production that there’s a multithreading bug.
Want to learn more?
From the author of Swift in Depth
Buy the Mobile System Design Book.
Learn about:
- Passing system design interviews
- Large app architectures
- Delivering reusable components
- How to avoid overengineering
- Dependency injection without fancy frameworks
- Saving time by delivering features faster
- And much more!
Suited for mobile engineers of all mobile platforms.

Conclusion
The moral of the story is: By decomposing to the tiniest testable part, you can mock at a granular level, meaning you are testing more production-code. It’s only one shift-left tactic, but it’s very effective.
I do recommend to only introduce a protocol for testing at the lowest level. This ensures you limit the testing protocols that you introduce. As opposed to, say, introducing a testing-protocol at every level in your stack.
A counterpoint: Running more production code inside unit-tests will probably slow down your testing. But that’s the trade-off, you’re testing more thoroughly, you keep the complexity lower, and your total software development cycle will be shorter.
There are plenty of perks; You’ll know earlier if things break, you can rely a bit less on integration tests to be confident (which are slower by nature). And if you catch a bug on your local machine, then you reduce the need to inform others or wait for the CI pipeline to tell you.
And you can mitigate slow unit-tests by only running specific tests.
Next time, I hope you can think of the tiniest piece to test, to shift your testing — in the famous words of Beyoncé — to the left, to the left.
Written by
Tjeerd in 't Veen has a background in product development inside startups, agencies, and enterprises. His roles included being a staff engineer at Twitter 1.0 and iOS Tech Lead at ING Bank.